MultiScraperSearch is a FastAPI project I built to search multiple movie/series sources from one place.
Instead of visiting each site separately, I can query once and get grouped results back from all connected scrapers.
Tech Stack
Python · Web Scraping · FastAPI · JSON
Live Demo
https://multiscrapersearch.onrender.com/
Source Code
https://github.com/SAJIBxD/MultiScraperSearch
Screenshot
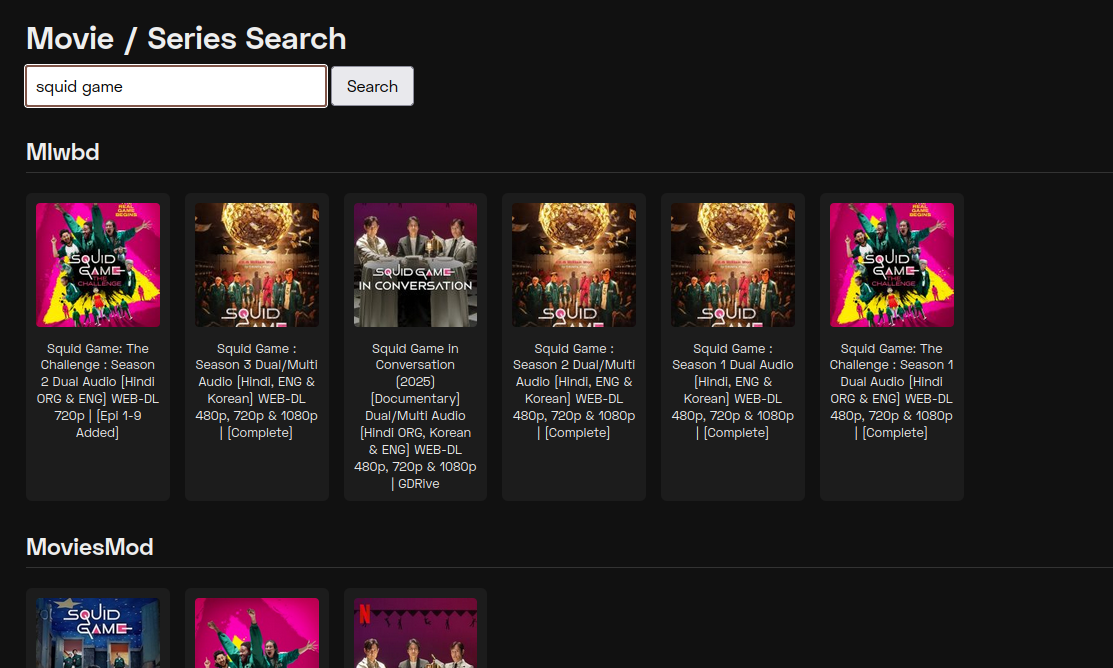
Search UI for querying multiple scraper sources from one place.
Core Features
- Single search endpoint:
/search/{query}. - Aggregates results from more than one scraper implementation.
- Returns structured JSON grouped by source name.
- Includes a minimal frontend (
/) to run searches and render result cards. - Opens result links in new tabs directly from each card.
How It Works
- User enters a keyword in the frontend.
- Frontend calls
/search/{query}. - Backend loops through registered scraper classes.
- Each scraper fetches and parses its target site.
- API returns source-wise grouped results, then the UI renders each section.
API Response Shape
The search response is a list of source objects, for example:
[
{
"mlwbd": [
{
"title": "...",
"url": "...",
"thumbnail": "..."
}
]
},
{
"MoviesMod": [
{
"title": "...",
"url": "...",
"thumbnail": "..."
}
]
}
]Implementation Notes
- Built with FastAPI and deployed on Render.
- Uses
requests+BeautifulSoup(lxml) for scraping. - Scraper logic is split into separate classes (
Mlwbd,MoviesMod). - Uses permissive CORS so the API is easier to consume from different clients.
- Serves a simple built-in frontend with
FileResponse("index.html").
Challenges & Learnings
- Every source has different HTML structure, so selectors cannot be reused blindly.
- Source markup changes over time, so scraper maintenance is part of the job.
- Returning results grouped by source made debugging much easier.
Next Improvements
- Add timeout/retry handling per source.
- Run source requests concurrently for better speed.
- Add caching for repeated queries.
- Add pagination/limits and cleaner normalization across sources.